

Table of Contents
AI marketing experiments are running at record volume in 2026, yet most of the wins never reach production at full strength. The pattern is becoming impossible to ignore. A new industry index released on May 13 puts hard numbers on a problem most B2B growth teams have been quietly absorbing for a year. The bottleneck is no longer the model, the creative, or the bid algorithm. The bottleneck is the data layer underneath the test.
For growth leaders trying to compound returns from AI, the fix is structural. This article walks through the 2026 evidence, the architecture that separates the top 20 percent of teams, and a five step audit any founder or head of growth can run this week.
The 2026 Data No One Is Putting on the Keynote Slide
On May 13, 2026, GrowthLoop published its 2026 AI and Marketing Performance Index. The headline numbers reframe how growth teams should evaluate every test that touches the AI stack.
Furthermore, the index shows 58 percent of marketers report spending a moderate or significant amount of time on experimentation. However, only 20 percent of those same marketers say their experimentation programs produce high impact. The drop off between effort and outcome is enormous.
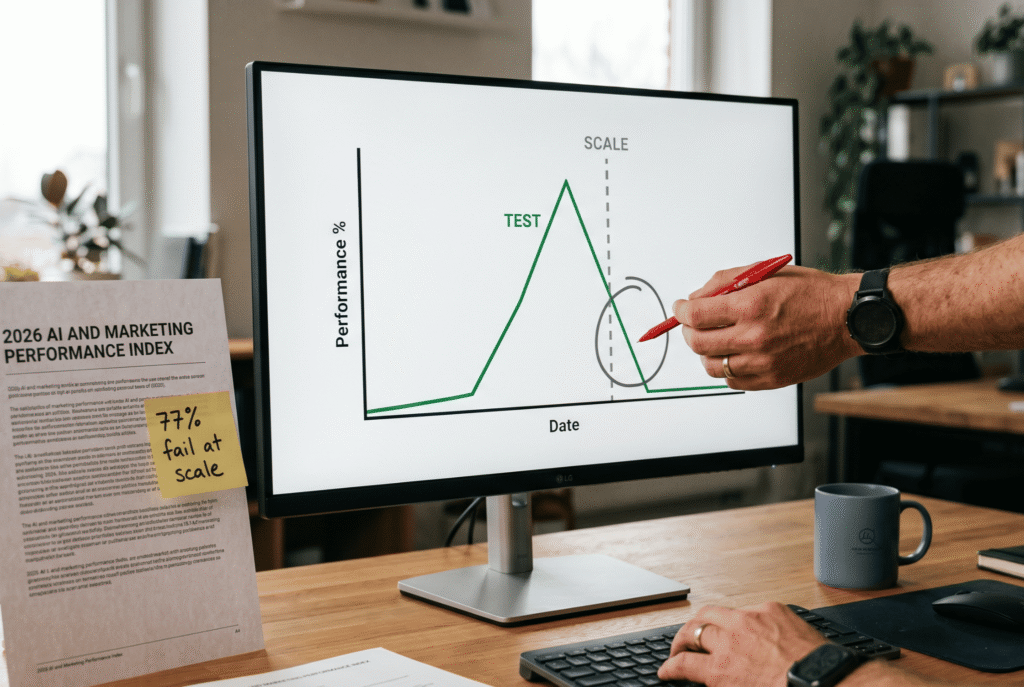
However, the most uncomfortable data point sits one layer deeper. Seventy seven percent of marketers say winning tests fail at scale at least sometimes. Furthermore, only 23 percent of marketers can reliably link marketing actions to business outcomes. In other words, three quarters of the field cannot trace cause to effect with confidence.
For context, the same week Google Marketing Live 2026 emphasised AI-driven decisioning across the Ads stack. The convergence is obvious. The industry is racing toward AI-driven activation while most teams cannot prove the activation works.
Why Winning Tests Collapse Between Lab and Production
The collapse pattern is repeatable. A test team builds a clean, hand crafted audience inside a notebook or a one-off SQL extract. The creative is sharp. The targeting is specific. The lift on conversion runs 12 to 30 percent in the test window. The team writes a memo and pushes the variant to production.
In contrast, production runs on a completely different customer model. The CRM segments are stale. Event tracking is partial. Identity is unresolved across web, product, and CRM. The audience the test relied on cannot be rebuilt in production with the same shape. As a result, the lift evaporates within seven to fourteen days. Teams blame creative fatigue, seasonality, or channel saturation. The real cause sits one layer below.
However, the deeper damage is cultural. Every failed scale event reduces confidence in the experimentation program itself. Budgets shift toward channels with simpler measurement, even when those channels carry lower potential lift. Teams stop testing the hardest hypotheses. The flywheel slows.
Therefore, the fix is not more tests. The fix is making the customer definition in production identical to the customer definition in the test environment.
The 20 Percent Who Get Real Lift From AI Marketing Experiments
Across the GrowthLoop data and field patterns Lumeneze sees in B2B growth engagements, three habits separate the top 20 percent of teams from the rest.
First, they treat the customer record as a product. There is one source of truth, owned by a single team, with explicit ownership of every attribute. For example, lifecycle stage is defined once, computed in the warehouse, and used by every channel. No team is allowed to recompute it inside an ad platform.
Second, they activate directly on the warehouse. The audience that runs the test is the audience that runs in production. Tools sync from a single, governed table. As a result, the lift travels because the input does not change between environments.
Third, they measure with causal methods. They run geo holdouts, switchback designs, or matched market tests. Last click attribution exists only as a debugging tool. Consequently, when a test shows lift, the lift is the actual contribution, not a correlation that vanishes at scale.
Consequently, these habits are not exotic. They are the foundation that allows the program to compound rather than churn. For founders, this is the difference between AI as a one-off tactic and AI as a real growth engine.
A Warehouse-Native Architecture That Survives Scale
Therefore, a simple architecture survives scale. The five components below are the minimum viable foundation for AI marketing experiments that hold up in production.
One, a unified customer record in the warehouse. Identity resolved across product, web, and CRM. A single primary key. Versioned attributes with clear ownership. In addition, this record is the only place new attributes get defined.
Two, a governed audience layer. Audiences are defined as SQL or DBT models on top of the unified record. They are reviewed like code. Furthermore, the same audience definition is exposed to every channel through reverse ETL or warehouse-native activation.
Three, an experimentation framework with causal measurement. Geo holdouts, switchback designs, or randomized cohort tests sit at the heart of the program. Therefore, lift is read with confidence intervals, not with vanity metrics.
Four, an AI decisioning layer that operates on the unified record. Models for next best action, propensity, and channel selection consume the same features the experimentation team uses. Consequently, what wins in test wins in deployment.
Five, a feedback loop. Outcomes flow back to the warehouse on a daily cadence. As a result, the audience layer and the decisioning layer learn from production reality, not from cached extracts.
For a deeper view of how Lumeneze builds this architecture inside B2B startups, see the Lumeneze growth systems approach.
How to Audit Your Experimentation Stack This Week
A founder or head of growth can run this audit in under three hours. The output tells you exactly where the program is leaking lift.
Step one. Pick a winning test from the last 90 days. Write down the audience definition exactly as it ran in the test.
Step two. Pull the audience that ran in production after the rollout. Compare row counts, key attributes, and segment composition. In contrast to test, where do they diverge?
Step three. Identify which attributes are computed inside an ad platform or a CSV upload, rather than in the warehouse. These are the leak points.
Step four. Check the attribution method used to declare the test a win. If it is last click, the lift is likely overstated. Consequently, the production drop is partly a reversion to truth.
Step five. Decide which one of the five architecture components is missing. Most teams are missing the unified customer record and the governed audience layer. Therefore that is usually the first fix.
As a result, finishing the audit gives you a defensible answer to one question every founder should be able to answer in 2026. Why do our AI marketing experiments survive scale, and which ones do not?
For a working session on this with the Lumeneze team, book a 15 minute call at calendly.com/ashikurrahaman/quick-intro. Bring one winning test and the production rollout numbers. You will leave with a specific architecture priority for the next 30 days.




